

How To Handle Missed Data In Python
This article was published every bit a role of the Data Science Blogathon
Introduction
Data Cleaning is the process of finding and correcting the inaccurate/incorrect data that are present in the dataset. One such process needed is to exercise something almost the values that are missing in the dataset. In real life, many datasets volition have many missing values, so dealing with them is an of import footstep.
Why practise you need to fill up in the missing data? Because most of the machine learning models that yous desire to utilise will provide an error if you laissez passer NaN values into it. The easiest way is to just fill up them up with 0, but this can reduce your model accuracy significantly.
For filling missing values, there are many methods available. For choosing the best method, you need to understand the type of missing value and its significance, before you commencement filling/deleting the data.
First Look at the Dataset
In this commodity, I will be working with the Titanic Dataset from Kaggle.
For downloading the dataset, use the following link – https://www.kaggle.com/c/titanic
- Import the required libraries that you volition exist using –
numpyandpandas.
import pandas as pd import numpy as np #importing the dataset into kaggle df = pd.read_csv("titanic_dataset.csv") df .head() 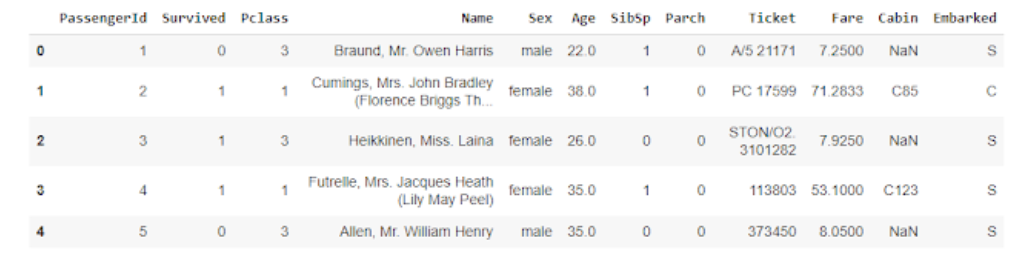
See that the contains many columns like PassengerId , Name , Age , etc.. We won't be working with all the columns in the dataset, so I am going to exist deleting the columns I don't need.
df.drib("Name",axis=1,inplace=True) df.drop("Ticket",axis=1,inplace=True) df.drop("PassengerId",centrality=1,inplace=Truthful) df.drib("Cabin",axis=ane,inplace=Truthful) df.drop("Embarked",axis=one,inplace=Truthful) See that there are also categorical values in the dataset, for this, yous demand to use Label Encoding or I Hot Encoding.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() df['Sex activity'] = le.fit_transform(df['Sex']) new df=df #splitting the information into x and y y = df[ 'Survived' ] df.driblet("Survived",centrality=ane,inplace=Truthful) How to know whether the information has missing values?
Missing values are ordinarily represented in the class of Nan or null or None in the dataset.
df.info() the function can be used to give information almost the dataset. This volition provide you with the column names along with the number of non – null values in each column.
df .info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total half-dozen columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pclass 891 non-null int64 i Sexual activity 891 non-null int64 two Age 714 non-aught float64 3 SibSp 891 non-null int64 4 Parch 891 non-zip int64 5 Fare 891 not-null float64 dtypes: float64(2), int64(4) retentivity usage: 41.ix KB Meet that there are nil values in the column Age.
The second way of finding whether nosotros have nada values in the data is by using the isnull() part.
print(df.isnull().sum()) Pclass 0 Sexual activity 0 Age 177 SibSp 0 Parch 0 Fare 0 dtype: int64 Run into that all the null values in the dataset are in the column – Age.
Allow's endeavour fitting the data using logistic regression.
from sklearn.model_selection import train_test_split X_train, X_test,y_train,y_test = train_test_split(df,y,test_size=0.three) from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train,y_train) --------------------------------------------------------------------------- ValueError: Input contains NaN, infinity or a value likewise big for dtype('float64'). Run into that the logistic regression model does non work every bit we have NaN values in the dataset. Only some of the machine learning algorithms can work with missing data like KNN, which will ignore the values with Nan values.
Now let'southward expect at the different methods that you tin can use to deal with the missing information.
The methods I will be discussing are
- Deleting the columns with missing information
- Deleting the rows with missing data
- Filling the missing data with a value – Imputation
- Imputation with an additional column
- Filling with a Regression Model
i. Deleting the column with missing data
In this case, let's delete the column, Age and then fit the model and check for accurateness.
But this is an extreme case and should just be used when there are many null values in the column.
updated_df = df.dropna(centrality=ane) updated_df .info() <form 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (full 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pclass 891 non-null int64 one Sex 891 non-nada int64 2 SibSp 891 non-null int64 3 Parch 891 non-naught int64 four Fare 891 non-zip float64 dtypes: float64(ane), int64(4) memory usage: 34.9 KB from sklearn import metrics from sklearn.model_selection import train_test_split X_train, X_test,y_train,y_test = train_test_split(updated_df,y,test_size=0.three) from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train,y_train) pred = lr.predict(X_test) print(metrics.accuracy_score(pred,y_test)) 0.7947761194029851 See that we are able to achieve an accuracy of 79.4%.
The problem with this method is that we may lose valuable data on that feature, as we take deleted it completely due to some zippo values.
Should only be used if in that location are too many null values.
2. Deleting the row with missing information
If there is a certain row with missing data, and then y'all tin delete the entire row with all the features in that row.
axis=ane is used to drop the column with `NaN` values.
axis=0 is used to drop the row with `NaN` values.
updated_df = new df.dropna(centrality=0) y1 = updated_df['Survived'] updated_df.drop("Survived",axis=i,inplace=True) updated_df .info() <class 'pandas.cadre.frame.DataFrame'> Int64Index: 714 entries, 0 to 890 Information columns (full 6 columns): # Cavalcade Non-Null Count Dtype --- ------ -------------- ----- 0 Pclass 714 non-null int64 i Sex 714 non-null int64 two Age 714 non-null float64 three SibSp 714 not-cipher int64 4 Parch 714 non-nix int64 five Fare 714 non-nix float64 dtypes: float64(2), int64(4) retentiveness usage: 39.0 KB from sklearn import metrics from sklearn.model_selection import train_test_split X_train, X_test,y_train,y_test = train_test_split(updated_df,y1,test_size=0.3) from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train,y_train) pred = lr.predict(X_test) impress(metrics.accuracy_score(pred,y_test)) 0.8232558139534883 In this case, come across that we are able to attain improve accuracy than before. This is maybe because the cavalcade Historic period contains more than valuable information than nosotros expected.
3. Filling the Missing Values – Imputation

In this case, we volition be filling the missing values with a certain number.
The possible ways to practice this are:
- Filling the missing data with the mean or median value if information technology's a numerical variable.
- Filling the missing data with way if it'due south a categorical value.
- Filling the numerical value with 0 or -999, or another number that will not occur in the data. This tin can be done and then that the machine can recognize that the data is not existent or is different.
- Filling the categorical value with a new type for the missing values.
You tin can utilize the fillna() role to fill the null values in the dataset.
updated_df = df updated_df['Age']=updated_df['Age'].fillna(updated_df['Age'].mean()) updated_df.info() <course 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Information columns (full vii columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Survived 891 non-null int64 1 Pclass 891 non-null int64 2 Sex 891 not-aught int64 iii Age 891 not-null float64 4 SibSp 891 non-null int64 v Parch 891 non-null int64 6 Fare 891 non-null float64 dtypes: float64(2), int64(5) memory usage: 48.nine KB y1 = updated_df['Survived'] updated_df.drop("Survived",axis=ane,inplace=True) from sklearn import metrics from sklearn.model_selection import train_test_split X_train, X_test,y_train,y_test = train_test_split(updated_df,y1,test_size=0.3) from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train,y_train) pred = lr.predict(X_test) print(metrics.accuracy_score(pred,y_test)) 0.7798507462686567 The accuracy value comes out to be 77.98% which is a reduction over the previous instance.
This will not happen in general, in this case, information technology means that the mean has not filled the null value properly.
4. Imputation with an boosted column
Use the SimpleImputer() function from sklearn module to impute the values.
Pass the strategy equally an argument to the function. It can be either mean or fashion or median.
The problem with the previous model is that the model does not know whether the values came from the original data or the imputed value. To make certain the model knows this, we are adding Ageismissing the column which will have True as value, if it is a null value and False if it is non a null value.
updated_df = df updated_df['Ageismissing'] = updated_df['Historic period'].isnull() from sklearn.impute import SimpleImputer my_imputer = SimpleImputer(strategy = 'median') data_new = my_imputer.fit_transform(updated_df) updated_df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 7 columns): # Column Not-Zilch Count Dtype --- ------ -------------- ----- 0 Pclass 891 non-aught int64 one Sexual activity 891 not-null int64 2 Age 891 non-goose egg float64 3 SibSp 891 not-nada int64 4 Parch 891 not-cipher int64 5 Fare 891 non-zippo float64 vi Ageismissing 891 non-null bool dtypes: bool(ane), float64(two), int64(4) memory usage: 42.8 KB from sklearn import metrics from sklearn.model_selection import train_test_split X_train, X_test,y_train,y_test = train_test_split(updated_df,y1,test_size=0.three) from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train,y_train) pred = lr.predict(X_test) print(metrics.accuracy_score(pred,y_test)) 0.7649253731343284 5. Filling with a Regression Model
In this example, the null values in one cavalcade are filled past plumbing equipment a regression model using other columns in the dataset.
I.E in this instance the regression model will incorporate all the columns except Age in 10 and Age in Y.
Then after filling the values in the Age column, then we will use logistic regression to summate accuracy.
from sklearn.linear_model import LinearRegression lr = LinearRegression() df.head() testdf = df[df['Age'].isnull()==True] traindf = df[df['Age'].isnull()==Simulated] y = traindf['Historic period'] traindf.drop("Age",axis=i,inplace=True) lr.fit(traindf,y) testdf.driblet("Age",axis=1,inplace=True) pred = lr.predict(testdf) testdf['Age']= pred 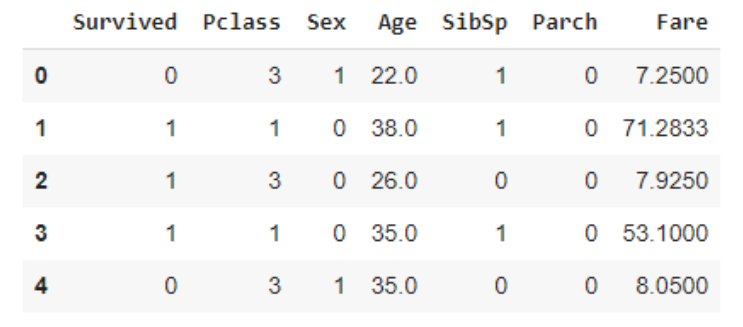
traindf['Age']=y y = traindf['Survived'] traindf.drop("Survived",centrality=1,inplace=True) from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(traindf,y) LogisticRegression(C=one.0, class_weight=None, dual=Fake, fit_intercept=Truthful, intercept_scaling=one, l1_ratio=None, max_iter=100, multi_class='car', n_jobs=None, penalty='l2', random_state=None, solver='lbfgs', tol=0.0001, verbose=0, warm_start=Faux) y_test = testdf['Survived'] testdf.driblet("Survived",axis=i,inplace=True) pred = lr.predict(testdf) impress(metrics.accuracy_score(pred,y_test)) 0.8361581920903954 See that this model produces more than accuracy than the previous model equally we are using a specific regression model for filling the missing values.
Nosotros can as well use models KNN for filling the missing values. But sometimes, using models for imputation can result in overfitting the data.
Imputing missing values using the regression model allowed us to improve our model compared to dropping those columns.
But y'all have to sympathize that There is no perfect way for filling the missing values in a dataset.
Each of the methods that I have discussed in this blog, may work well with dissimilar types of datasets. You take to experiment through different methods, to check which method works the all-time for your dataset.
Thanks for reading through the article. Hope y'all now accept a articulate understanding of how to deal with missing values in your dataset.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author's discretion.

How To Handle Missed Data In Python,
Source: https://www.analyticsvidhya.com/blog/2021/05/dealing-with-missing-values-in-python-a-complete-guide/
Posted by: brawnhoremill.blogspot.com
0 Response to "How To Handle Missed Data In Python"
Post a Comment